Generativ AI – tekniken, nya beteenden, upphovsrätten och kreatörernas oro
I slutet av 2022 lanserade Open AI sin språkgenerator ChatGPT publikt och den slog världen med häpnad. Artificiell intelligens, AI, slutade vara en fråga för techintresserade och blev i stället ett hett samtalsämne i stort sett överallt. Parallellt har andra AI-verktyg för bild- musik- och kodframställning blivit allt bättre och nått en bredare skara användare. När utvecklingen går så snabbt kan det vara svårt att överblicka läget: kommer generativ AI påverka vårt sätt att jobba? Kommer den konkurrera ut vissa kreativa yrkesroller? Hur ska upphovsrättsfrågan lösas? Vilka är riskerna? Möjligheterna? Kanske beror svaren på vem man frågar? Vi bestämde oss för att ta reda på det och kontaktade en branschföreträdare samt fyra experter på AI, upphovsrätt samt beteendeförändring.

Trots att de nya AI-botarna blivit så omtalade är det inte självklart att alla användare förstår hur de faktiskt fungerar, en förståelse som är viktig för en nyanserad syn på verktygens fördelar och nackdelar. Erik Ylipää, som forskar på AI på RISE (Research institutes of Sweden), förklarar generativ AI så här:
– Fråge-svarssystem som ChatGPT är språkmodeller som tränas för att skatta sannolikheten för texter. De hittar de mest sannolika ordföljderna baserat på sin träningsdata men har ingen direkt koppling till ”fakta” eller ”sanning”. Korrekta svar genereras om faktabaserad text finns i träningsdatan annars fabulerar modellen fram sannolika ordföljder. Det krävs mycket stora datamängder för att träna algoritmer i bild- och textgenerering.
Klicka för att läsa hela Eriks svar
”Generativ AI kan generera nya data som liknar existerande. Det fungerar genom att en datadriven algoritm lär sig kombinera ihop slumpmässiga egenskaper till trovärdiga helheter baserat på statistik. De uppmärksammade exemplen är bilder och texter, men generativ AI används inom många olika tillämpningar som exempelvis till att ge förslag på bioaktiva molekyler för läkemedelsutveckling eller mer användbara mikrostrukturer för kompositmaterial.
De fråge-svarssystem som uppmärksammats på senaste tid (främst ChatGPT) är i grunden så kallade språkmodeller som tränats till att försöka skatta hur sannolik en viss text är. Detta görs genom att gå igenom enorma mängder textdata och helt enkelt öka sannolikheten för att observera de ordföljder som förekommer i träningsdatamängden. Detta kan användas till att försöka hitta ordföljder (ett svar) som är mest sannolikt givet en annan ordföljd (en fråga). För den här typen av modell finns ingen direkt koppling till “fakta” eller “sanning”, bara mer eller mindre sannolika svar givet dess träningsdata. Det gör att modellen kan svara korrekt på frågor där det finns faktabaserad text i tillräcklig utsträckning i dess träningsdata. Problemet är att om den datan saknas kommer den ändå gladeligen att ge ett lika tvärsäkert svar genom att fabulera sig fram till de mest sannolika ordföljderna givet frågan.
Gemensamt för de generativa AI som uppmärksammats på senare tid är att de kan styras till att generera mer specifika data med hjälp av naturligt språk, det vill säga den typ av språk vi människor använder för att kommunicera med varandra. Det gör att de blir betydligt mer användbara för allmänheten. Det behövs inte längre expertkompetens inom AI-programmering för att kunna styra vad algoritmerna genererar.
För att lära algoritmerna vad de skall generera och utveckla den här typen av generativ AI krävs stora mängder data. För bildgenererande modeller används hundratals miljoner till miljarder par av text och bild, och för textgenererande modeller åtskilliga miljarder ord text.”
Att språkmodeller som ChatGPT kan ”hitta på” är ett fenomen som många uppmärksammat, Erik Ylipää tror dock inte att en lösning på det problemet ligger så långt bort.
– Det är ett aktivt forskningsfält, och jag tror produkter av samma kaliber som ChatGPT för detta kommer väldigt snart, detta eller nästa år. Vi ser redan att hundratals företag skapas som arbetar med att renodla teknikerna för användningar som behöver faktabaserade svar.
Det är dock inte bara trovärdigheten när det gäller fakta som kan utgöra ett problem, Erik Ylipää pekar också på en annan svaghet – de enorma datamängder som krävs för att träna modellerna och de skevheter som kan uppstå.
– Det behövs så enorma mängder att utvecklarna i stort sett dammsuger det publika internet på exempel. Det betyder att den data som används har ett fundamentalt urvalsproblem. Den är inte representativ för alla typer av data vi skulle kunna vilja generera utan har vissa snedvridningar baserat på vilket typ av bild och text som finns på internet. Dessa snedvridningar kan vara oerhört subtila, kanske i hur väl modellen kan skapa bilder med vissa teman eller hur väl den kan formulera svar på vissa frågor. Det i sin tur, kompletterat med olika urvalsfilter, kan göra att verktyget drar användaren åt vissa håll, vilket i sin tur kan få en självförstärkande effekt.
AI som kreatörskompis och konkurrent
AI kommer att påverka statusen, möjligheterna att ta betalt och försämra upphovsrätten. Det tror en majoritet av de visuella kreatörer som svarat på organisationens Svenska Tecknares nyligen genomförda enkätundersökning. Men det finns även de som ser möjligheter med den nya tekniken; som menar att det kan bli ett bollplank, ett skissverktyg eller ett sätt att effektivisera delar av den kreativa processen.
Klicka för att läsa mer om undersökningen
-
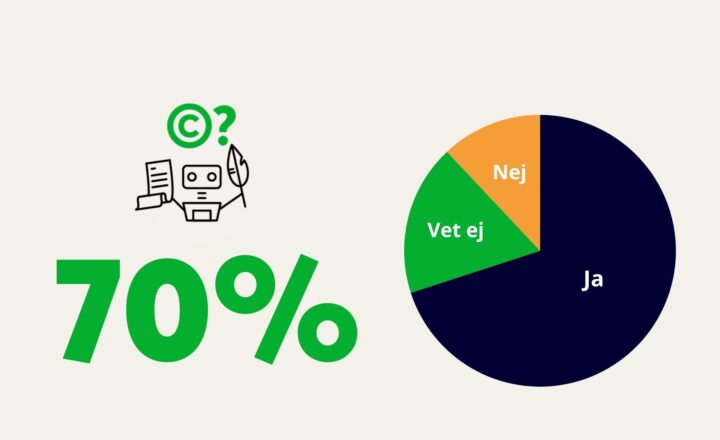
- Bland de 370 yrkesutövande som svarade på undersökningen* uppger mer än hälften att utvecklingen inom AI kommer att påverka yrkesrollen mer eller mindre negativt. 60 procent anser att AI utvecklingen kommer att påverka möjligheten att ta betalt inom yrket negativt och 64 procent tror att statusen inom yrkeskåren kommer att försämras. En majoritet tror även att upphovsrätten kommer att bli lidande och att det kommer bli svårare att behålla och få arbete inom sitt yrke.
- Närmare 90 procent uppger att deras verk finns att hitta genom sökmotorer på nätet. Bilder på nätet är en viktig källa till hur AI-verktygen tränats upp. Över 70 procent av de som svarade på undersökningen säger att de är negativa till att AI-verktyg tränas upp med hjälp av deras bilder utan deras medgivande. Men fler ställer sig positiva till det om de skulle få betalt för att deras bilder används.
- Samtidigt som många upplever AI som ett hot är det också en hel del som ser möjligheter med den nya tekniken. ”Att ha AI-motorer i program gör mitt jobb som animatör lättare”, ”Jag ser fördelar med att använda AI som skissverktyg” och ”En fördel kan vara att det är möjligt att snabbt generera verk baserade på mitt eget manér” är åsikter som uttrycks bland frisvaren i undersökningen.
- Enkätundersökningen visar även att visuella kreatörer upplever att AI är här för att stanna och att många vill lära sig mer om hur man använder verktygen. De flesta tror att AI kommer att göra så att de behöver anpassa sitt arbete i framtiden.
* Enkätundersökning, Svenska Tecknare, mars 2023
Sandra Nolgren, verksamhetsledare på Svenska Tecknare, har stor förståelse för att visuella kreatörer kan känna sig oroliga och menar att det inte bara handlar om att det blir mycket lättare för folk i allmänhet att skapa bilder.
– Det finns också farhågor om att det kommer att finnas en förväntan om att allt nu ska gå mycket snabbare. Att det ska ställas orimliga krav på korta leveranstider och att det ska bli svårare att motivera varför jag som mänsklig kreatör ska ha betalt för 10 timmar för att göra något när AI-programmet kan göra det på en timme. Det är ett perspektiv som kan leda till prisdumpning.

Möjligen kan en parallell dras till den första vågen av digitalisering när ny programvara, digitalkameror och kraftfull fri distribution på webben gjorde bilden till en stapelvara. Sandra Nolgren tycker att det är bra att bilden fått ett större utrymme i samhället och blivit mer lättillgänglig men menar också att det uppfattade värdet på den enskilda bilden har minskat.
– Jag tittade på 20 år gamla arvodesundersökningar och arvodena då var lika höga eller högre än vad folk får idag. På det sättet har det ju faktiskt skett en stagnation inom arvoderingen, och det kan man ju delvis koppla till digitaliseringen. Förutom inflation och andra faktorer har inte ersättningen höjts i takt med det merarbete som digitaliseringen fört med sig för kreatörer – exempelvis att du kanske måste leverera många fler format och att det blir mycket större spridning av ditt material.
Hon tror också att förhållningssättet till den nya tekniken till viss del beror på hur ens verksamhet och arbetsprocess ser ut.
– En animatör med flera tidsödande ”mekaniska” delar i processen kanske ser mer möjligheter med AI än en barnboksillustratör med en mer traditionellt konstnärlig process, till exempel. Det finns även de som i undersökningen påpekade att det så småningom kan komma en allmän motreaktion, att det som är skapat av människor kan bli mer exklusivt och få en ökad status.
Idag, innan vi får se en eventuell tydlig motreaktion mot AI-utvecklingen, ser vi dock att många som livnär sig på visuell kreation är oroliga och menar att marknaden kommer att förändras. Håller forskaren Erik Ylipää med om den bedömningen?
– Ja, jag tror bildgenererande AI är det som för tillfället konkurrerar mest med människor, främst inom tidiga faser av större projekt. Exempelvis har stora spelutvecklare länge anställt konceptkonstnärer för att skissa fram en större värld, men nu kan en stor del av det arbetet outsourcas till generativa bildmodeller. Digitala bildkonstnärer som fått inkomst genom beställningsarbeten (till bokomslag, porträtt till rollpersoner etcetera) kommer nog också se en minskad efterfrågan, vilket påverkar en grupp som redan levt under otrygga arbetsförhållanden.

Men hur ser det då ut när det gäller text? Mycket av uppmärksamheten på sistone har ju gällt ChatGPT och dess förmåga att sätta ihop rimliga textsvar inom alla möjliga områden. Erik Ylipää tror att verktygen i nuläget mest kommer att användas av de som redan tar fram texter för att höja produktiviteten.
– Om den ökade produktiviteten kommer att leda till ett minskat behov av copywriters och andra skribenter, eller om det kommer leda till fler texter av högre kvalitet återstår att se. För att text skall passa bra i exempelvis annonser eller en produktbeskrivning tror jag fortfarande att en människa är central då textförfattandet bara är en del i vad det innebär att ta fram en bra annons. En möjlig utveckling är att det blir betydligt mer tillgängligt för “vem som helst” att skapa själva texten, vilket gör tjänsterna kring att se till att den når ut mer efterfrågade.
Kan man se på en text om den är skriven av AI? Klicka för att läsa svaret.
Erik Ylipää: ”Det finns försök att skapa så kallade AI-klassificerare, men det är en ansträngning som så småningom kommer att misslyckas. De existerande algoritmerna för det här presterar redan rätt dåligt (de tenderar att skatta människogenererad text som artificiella alldeles för ofta) och så fort en bra klassificerare skapas kan den generativa modellen tränas till att minimera dess träffsäkerhet om syftet är att undgå detektion.
För ChatGPT tenderar svaren att följa en viss struktur på en direkt ställd fråga och det går ibland att se när det händer. Det går dock ofta att drastiskt kringgå det fenomenet genom att formulera om frågan och be ChatGPT att svara på ett visst sätt, och så kallad ’prompt engineering’ går framåt oerhört fort, där de som har som mål att dölja att det handlar om automatgenererad text delar med sig av sina bästa tips.”
Ökad produktivitet, större effektivitet, snabbare processer och kraftfulla verktyg som blir tillgängliga för alla är något som både Erik Ylipää och Sandra Nolgren nämner i anslutning till AI. Kommer detta slutligen att förändra vår syn på kreativitet och originalitet i grunden? Niklas Laninge, psykolog och medgrundare av Nordic Behaviour Group, tror inte det:

– Jag tror att den klassiska definitionen av kreativitet kommer att stå pall för AI-revolutionen, det vill säga att det skapade är något nytt och användbart. Kraven lär dock öka på kvalitet och utförande. Lite på samma sätt som nya tekniker och genvägar alltid påverkat synen på var lägstanivån ligger i förhållande till det som skapats, och därmed också minskat värdet på dussinkreationer.
Niklas Laninge lyfter i stället ett annat perspektiv där han tror att generativ AI kan få strukturella konsekvenser – en ny situation där stora mängder originalverk endast utgör inspiration till en AI.
– Ser jag till risker för kreatörer så tänker jag att denna våg av generativ AI kan störa en central incitamentsstruktur. Man skapar ju för att bli läst, lyssnad på och så vidare. Det vill säga inte enbart för pengarnas skull, även om det är viktigt, utan även för att det är belönande i sig att uttrycka sig och att synlighet kan göra det lättare att ”bli upptäckt”. Hur blir det i en framtid där många som skapar originella idéer, texter och bilder främst når ut genom att en AI tuggar i sig ens verk och väver in det i sina svar utan att någonsin hänvisa till ursprungskällan?
Att skapa och vilja bli sedda är å andra sidan ett så grundläggande psykologiskt behov att vi sannolikt alltid kommer vilja fortsätta vara kreativa och uttrycka oss, menar Niklas Laninge.
– Jag är inte superorolig men jag tänker på att vi levt i en tid då väldigt många främst skriver innehåll vars enda läsare är Googles sökalgoritm, och den kan ju trots allt även leda mänskliga läsare till texten. Det känns smått dystopiskt att nästa steg blir att den enda läsaren blir OpenAI:s ChatGPT.

AI och kunskapsförmedling
I media är det just nu ett stort fokus på just de kreativa, konstnärliga konsekvenserna av AI-utvecklingen. Men AI används också alltmer för att sammanställa, processa och förmedla kunskap och data. Gabriella Stuart är beteendestrateg på Nordic Behaviour Group och forskningsassistent i ett internationellt projekt som integrerar datavetenskap, maskininlärning och beteendevetenskap. Syftet med projektet är att med hjälp av artificiell intelligens ta fram en databas som ska tillgängliggöra befintlig forskning inom beteendeförändring. Projektets första fas fokuserar på forskning kring rökning och fysisk aktivitet.
– Att överblicka och vara uppdaterad kring forskningen inom beteendeförändring är i vanliga fall svårt eftersom det kommer ny forskning hela tiden i en hög takt, men nu lär vi det här systemet att identifiera och samla in alla nya och relevanta studier. På så sätt kommer vi till slut att ha en stor databas som ständigt uppdateras med ny forskning allteftersom. Sedan är målet att man ska kunna ställa frågor till systemet, exempelvis vilka typer av interventioner som fungerar bäst när det gäller att hjälpa människor att sluta röka. Genom att forskningen blir mer tillgänglig på det här sättet blir det också enklare för yrkesprofessionella att fatta evidensbaserade beslut.

Gabriella Stuart tror inte att denna typ av smarta databaser kommer att göra alla beslutsfattare, oberoende av förkunskaper, helt självständiga. Det kommer fortfarande finnas ett behov av att kunna tolka och sätta de svar och rekommendationer man får i en kontext. Däremot kan andra yrkesgrupper, som journalister och författare av faktaböcker, få viss konkurrens, menar Niklas Laninge:
– Jag har exempelvis själv skrivit många populärvetenskapliga böcker, och en viktig funktion de fyller är att sammanfatta ett ofta komplext forskningsläge i mer lättillgängliga insikter: Vad har vi lärt oss? Vad funkar? Men nu blir ju de här böckerna väldigt snabbt daterade. Om en AI både kan ge oss rekommendationer om hur vi utifrån evidens kan lösa olika problem och samtidigt sammanfattar ett kunskapsområde i realtid blir det en stor konkurrent till författare av populärvetenskap och faktaböcker. Sedan läser man ju sådana böcker för nöjes skull också, så det personliga uttrycket kommer ju vara fortsatt viktigt för många.
Erik Ylipää är inne på samma nyanserade spår – att AI kommer att leda till förändringar, men inte nödvändigtvis i termer av olika yrkesrollers vara eller inte vara.
– Utvecklingen av AI kan visst leda till nya yrkesgrupper, som promptdesigner, men det är mer troligt att dessa färdigheter utvecklas inom befintliga, komplexa yrkesroller. En ny yrkesgrupp som faktiskt redan vuxit fram är ”AI-tränare”, som arbetar med att förbättra träningsdata för algoritmer. Beroende på vilken typ av data som behövs kan specialister vara involverade i tillfälliga projekt för att sammanställa sådan data, till exempel inom medicin. Det är dock viktigt att notera att datadrivna metoder inte kommer att ersätta komplexa yrkesroller helt och hållet, utan snarare fungera som stöd för specifika arbetsuppgifter inom dessa roller.
Just rollen som stöd i samband med problemlösning, research och vissa kreativa processer poängteras av Niklas Laninge som ser att AI kan bli ett naturligt första bollplank för många.
– En teknologi som lyckats samla enorma mängder mänskliga idéer, tankar och formuleringar – det är helt enkelt en bra sparringpartner. Men, då får man inte glömma de svagheter de här systemen har och källkritik kommer att bli ännu mer komplext och viktigt. Att vara källkritisk till vad jag hittar via en Googlelänk är en helt annan sak än att förhålla mig till en språkmodell som genererat en sammanfattning av tusentals källor.
AI och upphovsrätten
Många menar att den snabba AI-utvecklingen har lett till ett upphovsrättsligt vakuum, en del skulle till och med säga kaos. Johan Axhamn, juris doktor och universitetslektor i handelsrätt på Ekonomihögskolan vid Lunds universitet, pekar på att vägledning i vissa delar ändå finns.
– Svensk och europeisk upphovsrätt har nyligen uppdaterats med avseende på en aspekt som aktualiseras i samband med artificiell intelligens. Det handlar om bestämmelser om så kallad text- och datautvinning. Text- och datautvinning aktualiseras exempelvis i samband med att befintliga verk och annat upphovsrättsligt skyddat material används som träningsdata för utveckling av artificiell intelligens. De nya reglerna innebär bland annat att det är möjligt att använda befintliga verk med mera som träningsdata, såvida inte upphovsmännen har motsatt sig sådan användning. Det finns också, enligt särskilda regler, möjlighet för forskningsorganisationer att genomföra sådan användning oavsett om upphovsmännen har motsatt sig sådan användning eller inte.

Johan Axhamn konstaterar dock att upphovsrätten däremot inte har uppdaterats ännu när det gäller AI-output i form av text och bilder. Det vill säga om AI:ns output kan eller bör kunna åtnjuta upphovsrätt eller ett upphovsrättsliknande skydd, exempelvis genom någon form av så kallad närstående rättighet. Med det senare avses rättigheter som påminner om upphovsrättsligt skydd, men som inte förutsätter en skapande, kreativ insats utan i stället är resultatet av en viss arbetsinsats eller en investering; det kan exempelvis handla om rättigheter för utövande konstnärer och skiv- och filmproducenter.
– Allmänt gäller förstås att om AI-output i det enskilda fallet är resultatet av tillräcklig mänsklig kreativitet i form av fria och kreativa val i samband med skapandet, så kan outputen uppfylla kraven för upphovsrättsligt skydd som verk. Men de AI-verktyg som har utvecklats på senare tid är så pass självständiga (autonoma) att utrymmet för mänsklig kreativitet, som påverkar slutresultatet, är mycket begränsat. Mänsklig input i form av en textpromt motsvarar i förhållande till slutresultatet närmast bakomliggande idéer och liknande som inte kan skyddas av upphovsrätt. Däremot skulle mänsklig input i form av feedback till AI:n, eller kreativ bearbetning av AI:ns output, möjligen kunna rendera upphovsrättsligt skydd för den som ger feedbacken eller genomför bearbetningen.
Om det skulle bli aktuellt att införa ett särskilt skydd för AI-output så uppstår frågan vem som blir ursprunglig rättighetshavare; den som utvecklat AI:n, den som äger AI:n eller den som använder AI:n i det enskilda fallet? Johan Axhamn menar att det i grunden är en rättspolitisk fråga om vilka insatser som ska främjas och belönas med ett upphovsrättsliknande skydd. Att det redan finns så kallade närstående rättigheter är exempel på att det upphovsrättsliga regelverket över tid har utvecklats och anpassats för att ge skydd också för insatser som inte förutsätter mänsklig kreativitet.
Klicka här för att läsa mer upphovsrättsligt skydd för AI-genererade verk
Johan Axhamn: ”I grunden är det en rättspolitisk fråga vilka insatser som ska främjas och belönas med rättigheter av upphovsrättsligt slag: den som utvecklat AI:n, den som äger AI:n eller den som använder AI:n i det enskilda fallet. Det behöver också vara ett regelverk som går att efterleva i praktiken. Jag har inte slutligt landat i vad jag tycker här, men om det ska införas ett särskilt (nytt skydd) för AI-genererad output så leder det möjligen och sannolikt till minst tillämpningsproblem om det är den person som använder AI:n som blir rättighetshavare. Samtidigt skulle då ske en urvattning av gränsen mellan idé och uttryck; att ”endast” ge en instruktion till ett AI-verktyg – exempelvis i form av en textprompt – motsvarar nämligen närmast att stå för en bakomliggande idé.
I akademiska kretsar har föreslagits att en ”lösning”, för åtminstone en del av problematiken, skulle kunna vara att ta bort den så kallade presumtionsregeln om upphovsmannaskap. Bestämmelsen, som finns i 7 § upphovsrättslagen (se ovan), har sin motsvarighet i den internationella Bernkonventionen om litterära och konstnärliga verk. Det finns en risk att presumtionsregeln ”missbrukas” av personer som använder AI-verktyg och där AI-outputen egentligen inte ger uttryck för tillräcklig bakomliggande mänsklig kreativitet; alltså att personerna anger sig själva som upphovsmän, även om slutresultatet egentligen inte åtnjuter upphovsrättsligt skydd. Att ta bort presumtionsregeln skulle innebära att den som påstår sig vara upphovsman också skulle ha bevisbördan för det. Presumtionsregeln har dock så pass stor betydelse för upphovsrättens praktiska tillämpning, bl.a. i fråga om att underlätta för enskilda upphovsmän att kunna åtnjuta det upphovsrättsliga skyddet, att jag inte bedömer att det är en rimlig väg framåt att ta bort denna bestämmelse. Det är inte heller realistiskt – bland annat av politiska skäl – att öppna upp Bernkonventionen för omförhandling.”
En ytterligare fråga som har aktualiserats i samband med användning av AI för generering av exempelvis bilder är att upphovsrätten inte skyddar stil och manér. Det upphovsrättsliga skyddet sträcker sig endast till konkreta uttryck; inte den stil eller det manér som flera bilder gemensamt ger uttryck för. Flera av de AI-verktyg som finns på marknaden kan generera texter och bilder som påminner om kända upphovsmäns ”stilar”. Men så länge det nya innehållet inte är tillräckligt likt ett konkret verk (som använts som input) så föreligger inte upphovsrättsintrång.
– Det är också ett potentiellt problem att det på marknaden förekommer bilder och annat som ser ut som upphovsrättsligt skyddade bilder; där det mänskliga ögat inte kan avgöra om det är en människa eller en AI som genererat bilden. Det kan också förekomma ”missbruk” av den så kallade presumtionsregeln i upphovsrättslagen. Denna regel innebär att ”såsom upphovsman anses, där ej annat visas, den vars namn eller ock allmänt kända pseudonym eller signatur på sedvanligt sätt utsättes på exemplar av verket eller angives då detta göres tillgängligt för allmänheten.” Det är exempelvis inte osannolikt att personer som har använt AI för att generera exempelvis bilder sätter sitt namn på bilden, eller på annat sätt anger eller uppger sig vara upphovsperson – trots att deras egen insats inte uppfyller kraven som krävs för upphovsmannaskap.
Kommer dessa potentiella problem och otydligheter vad gäller vardagspraktik kräva ändringar i det upphovsrättsliga regelverket? Johan Axhamn menar att det finns anledning att överväga kompletteringar.
– Jag tror att det kan behövas ett förtydligande i lagen om vad som gäller för AI-genererad output. Den nuvarande ordningen – där en bedömning behöver göras i varje enskilt fall om det finns tillräcklig mänsklig input – är sannolikt alltför osäker inom ett område som får allt mer praktisk och ekonomisk betydelse. Det gäller särskilt eftersom det endast är en av parterna – i praktiken den som har utvecklat eller använder AI:n i det enskilda fallet – som har information om hur skapandet eller genereringen gick till. Det är ett betydande så kallat informationsasymmetriskt problem. Den nuvarande presumtionsregeln kan alltså tyvärr bidra till alltför stor osäkerhet om huruvida ett visst innehåll faktiskt omfattas av upphovsrätt. I likhet med andra regler på upphovsrättsområdet så behövs det sannolikt gemensamma regler på EU- och eventuellt också internationell nivå i syfte att främja gränsöverskridande handel med mera.
Sandra Nolgren och Svenska Tecknare, som representerar många av de upphovsrättsinnehavare som berörs av både AI-utvecklingen och de nya reglerna på upphovsrättsområdet, säger att de just nu ser över hur situationen för kreatörerna kan stärkas.
– Vi tittar på om det går att ta fram effektiva rutiner för upphovsrättsinnehavare som vill begära opt-out, det vill säga förbjuda användning av deras verk i samband med träning av generativ AI. Vi undersöker även möjligheterna till någon form av system för licensiering av verk till AI.
Framtiden – möjligheter och risker
Ett antal forskare och techprofiler gick nyligen ut och varnade för riskerna med den snabba AI-utvecklingen. De menar att det är nödvändigt att pausa arbetet för att samhället ska få en chans att komma ifatt. Hur ser AI-forskaren Erik Ylipää på riskerna?
– De största riskerna jag ser med AI-utvecklingen är maktkoncentration, brist på tillgång till data, och snedvriden representation i träningsdata. Datadrivna metoder kräver stora mängder data, vilket innebär att de som kontrollerar dessa datamängder har större möjlighet att utveckla avancerad AI. Detta skapar en ”first-mover advantage” och riskerar att ge upphov till monopol inom AI-tjänster, likt hur sökmotorer på internet dominerats av en enskild aktör.
Läs hela Erik Ylipääs svar om risker med AI
”De stora riskerna som jag ser det ligger i vem som kontrollerar verktygen. Det här är ytterligare ett produktivitetssprång jämfört med digitaliseringen, men kopplingen till data gör det mer utmanande än när det handlade om att utveckla regelbaserad mjukvara. Med mjukvara och kunnande var det från och med 1990-talet en enkel sak att skräddarsy ett system baserat på öppna tekniker (programmeringsspråk med öppna kompilatorer, hårdvara utan monopol) vilket ledde till en decentralisering av digitaliseringen.
Med datadrivna metoder kan vi inte göra något utan stora mängder av data, och de som äger de stora datamängderna delar inte med sig av dem, dels för att det är en enorm affärsfördel och dels för att de inte får dela data om användare. De som har råd att lägga stora mängder pengar på att bygga stora interna datamängder kan också utveckla den bästa AI:n, vilket leder till en risk för “first-mover-advantage”. Med de framgångar OpenAI haft med ChatGPT är det svårt för konkurrenter att slå sig in i fältet, vilket leder till större intäkter till OpenAI, vilket leder till att de kan investera ännu mer i sin modell. Det är möjligt att vi kommer se samma typ av monopol som dominerat sökning på internet också inom AI-tjänster så länge det inte finns stora öppna mängder data som kan användas till att träna modellerna.
Den nuvarande utvecklingen gör det också svårt för mindre oberoende forskargrupper att bidra till utvecklingen. Den mängd data och beräkningskraft som behövs för att utveckla den här typen av AI är alldeles för kostsam för att mindre forskningsprojekt skall kunna hålla jämna steg, vilket leder till en utarmning av den akademiska AI-forskningen till förmån för den industriella.
Ett fundamentalt problem är också att den data som modellerna tränas med är snedvriden. Den tenderar att representera en viss del av mänskligheten, med ett företrädesvis västerländskt, ungt och tekniktillvänt perspektiv. Mer ovanliga perspektiv, som minoritetsgrupper och minoritetsspråk, blir en försvinnande liten del i de här datamängderna och riskerar att drunkna i den statistik som modellerna drivs av. Till det läggs den aktiva datainsamlingen som exempelvis OpenAI gör, där de mänskliga data-annoterarna ges tydliga policies i hur de skall formulera typsvar som ChatGPT tränas på. Ur ett liberalt demokratiskt synsätt är OpenAIs policy god, men det är lätt att se hur exakt samma metod kan användas för att utveckla träningsdata som förstärker ett helt annat synsätt på världen, med en exempelvis totalitär ickedemokratisk policy. En av de ledande nationerna inom utveckling av AI är Kina, och frågan är vilken sorts snedvridning den motsvarande ChatGPT skapad av exempelvis Baidu kommer besitta. Vad kommer den svara på frågor som “Vad hände på Himmelska Fridens Torg sommaren 1989?”
Jag tror inte att “stark generell AI” är ett övervägande hot. De artificiella intelligenser vi utvecklar nu är väldigt annorlunda från mänsklig intelligens, och jag tror att de starka drivkrafterna är att utveckla verktyg som kompletterar människors intelligens. Precis som de flygande maskiner vi har inte flaxar med vingarna tror jag inte att vi kommer att bygga maskiner i stor skala som har människoliknande intelligens.”
Erik Ylipää menar också att generativ AI, trots riskerna, rymmer enorma möjligheter.
– Jag tror att den här typen av verktyg kommer vara en lika stor del av vår vardag som sökmotorer varit. Vi kommer se en plötslig explosion av nya verktyg för att interagera med text och det kommer skapa svallvågor genom alla de system som påverkas av text. System som beror på ansökningar skrivna i text kommer kanske överbelastas, sociala medier kommer späs ut av ännu fler botar. Det massmediala landskapet om fem år är oerhört svårt att sia om.
Han menar dock att det är viktigt att inte låta förväntningarna bli för höga.
– Det är lätt att övergå till science fiction-scenarier när man funderar över teknikens framtid. AI kommer troligen att ha störst positiv påverkan inom specialiserade tillämpningar, särskilt inom avancerade områden som Life Science och olika ingenjörsdiscipliner. Med AI:s hjälp kommer människor som arbetar inom dessa områden att kunna göra betydligt större framsteg.
Niklas Laninge ser också stora möjligheter med utvecklingen och beskriver det som att vi är mitt inne i ett stort paradigmskifte, ett tekniksprång. Han nämner dels den typ av projekt som hans kollega Gabriella Stuart är inne i och den allmänna känslan av att vara i början av en omvälvande utveckling. När det gäller risker pekar han på de osäkerhetsfaktorer som omger dagens språkmodeller.
– Det är tydligt att det krävs domänspecifik kunskap för att faktiskt kunna avgöra när exempelvis Chat GPT har rätt, skarvar eller är helt fel ute. Precis som vi redan nu lärt oss att vara skeptiska kring vissa avsändare och vara vaksamma på att olika röster är biased så måste vi snabbt som attan fatta att detsamma gäller för de dataset som AI-tränas på.
Ett annat medskick från Niklas Laninge är att vi måste hålla koll på vår tendens att i vår iver springa ifrån oss själva.
– Vi behöver vara försiktiga med var vi lägger vårt fokus. Ny teknologi är spännande och det kan vara lätt att bli lite för optimistisk när det gäller teknikens potential att driva beteendeförändringar. Oavsett om det gäller appar eller AI slarvas det ofta med grundläggande frågor som: Varför beter sig människor i målgruppen som de gör? Hur ser deras behov ut? Det blir verkligen ett problem när tjänster eller produkter inte är människocentrerade och man går direkt på lösningar. Resultatet kan då i slutändan bli något som ingen använder då det inte svarar mot något verkligt behov.
Kanske finns det ändå tröst att hämta i insikter från det teknikskifte som ägde rum för inte allt för länge sedan. Erik Ylipää menar att det finns en vinnande kombination som står sig:
– En viktig lärdom från digitaliseringen som jag tror fortsatt kommer att hålla är att samarbetet mellan maskin och människa är mycket kraftfullare än det mellan maskiner.
Förhoppningsvis har han rätt. Då finns det en strimma hopp för mänskligheten, även i en situation då maskiner kan göra mycket av det vi kan bättre, snabbare och effektivare.

Bonusnytt – det senaste om upphovsrätt direkt i mailen
Nyhetsbrevet Bonusnytt skickas ut cirka 8 gånger per år och innehåller omvärldsbevakning kring bransch- och upphovsrättsfrågor, samt intervjuer och insikter från undersökningar och rapporter.
Medverkande
Erik Ylipää, AI-forskare på RISE
Sandra Nolgren, verksamhetsledare på Svenska Tecknare
Niklas Laninge, psykolog och medgrundare av Nordic Behaviour Group
Gabriella Stuart, forskningsassistent och beteendestrateg på Nordic Behaviour Group
Johan Axhamn, juris doktor och universitetslektor i handelsrätt på Ekonomihögskolan vid Lunds universitet